Concept note / early-stage research (2025): Marginal Hierarchical Reinforcement Learning for Asymmetric Multi-Agent Systems
Summary
In classical multi-agent reinforcement learning (MARL), agents share the same learning framework but operate under fixed computational and communication assumptions. Real systems are rarely homogeneous. Each autonomous unit—drone, robot, vehicle—has different resources, observation limits, and safety requirements. The proposed concept, Marginal Hierarchical Reinforcement Learning (M-HRL), treats computation as a scarce, allocatable resource.
Abstract
In classical multi-agent reinforcement learning (MARL), agents share the same learning framework but operate under fixed computational and communication assumptions. Real-world systems, however, are rarely homogeneous. Each autonomous unit—be it a drone, robot, or vehicle—possesses different resources, observation limits, and safety requirements. This asymmetry introduces a challenge that conventional MARL fails to address: how to coordinate when computation itself becomes a scarce and distributable resource.
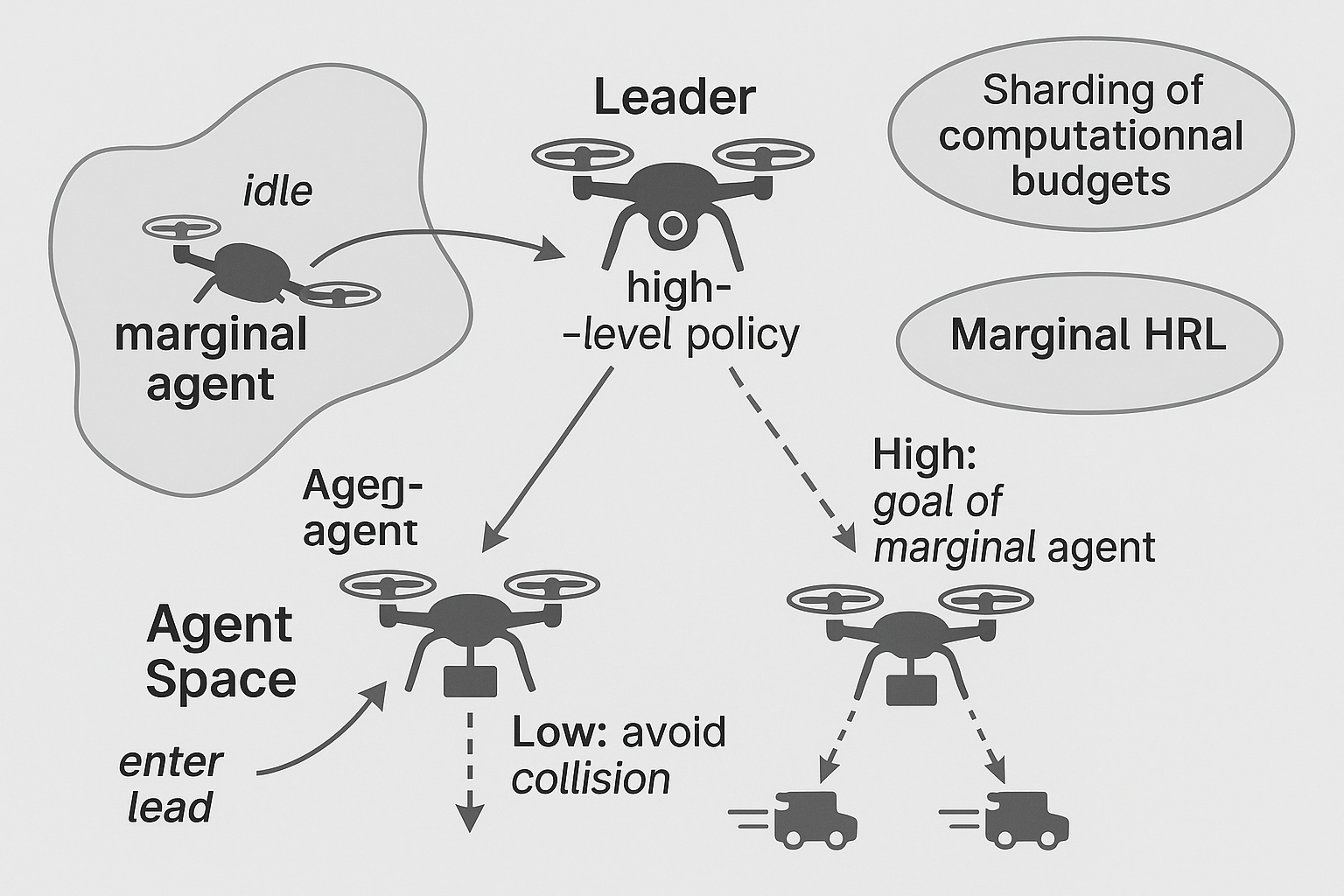
The proposed concept, Marginal Hierarchical Reinforcement Learning (M-HRL), extends the standard hierarchical RL paradigm beyond temporal or spatial decomposition. Instead of structuring policies around subgoals, it structures them around computational priorities. A leader agent dynamically allocates the available “budget” between safety and task-oriented layers across the coalition. The safety layer ensures collision-free motion, while the task layer focuses on mission optimization. This yields a lexicographic hierarchy of control: safety dominates reward pursuit.
Unlike pure swarm algorithms, which rely solely on local interactions, M-HRL maintains a soft form of centrality. Leadership is not permanent; it migrates based on connection quality and agent reliability. Thus, the system avoids both extremes: full decentralization (which risks incoherence) and total centralization (which risks fragility). This creates a self-stabilizing architecture—one that can tolerate communication loss and recover coordination through distributed election.
Philosophically, this design echoes Arrow’s Impossibility Theorem: no collective decision can satisfy all fairness axioms simultaneously. The leader’s computational authority is a pragmatic compromise—an “engineered dictatorship” of resources that preserves collective safety under rational constraints. Marginal HRL thus stands at the intersection of control theory, game theory, and machine intelligence, representing a step toward adaptive, resource-aware collectives capable of both autonomy and coherence.
Key Idea
M-HRL extends hierarchical RL beyond temporal/spatial subgoals toward computational priorities:
- A leader forms a dynamic coalition and allocates the available budget between two layers:
- Safety Layer — collision avoidance with hard priority.
- Task Layer — mission optimization with adaptive share.
- The overall control is lexicographic: safety dominates reward pursuit.
- Leadership is transferable under link loss or degraded quality (handover).
Architecture (sketch)
- CTDE training; decentralized execution.
- Coalition selection + budget allocation ((b^S \ge b_{\min},\; b^T \ge 0)).
- Merged action (a=\Phi(a^S,a^T)), safety-first.
References:
- Loginov, M. (2025). Marginal Hierarchical Reinforcement Learning for Asymmetric Multi-Agent Systems (Concept Note). For collaboration or feedback please contact the page of the site.