Many real-world systems—industrial infrastructure, maintenance operations, logistics networks, and complex technical installations—operate in environments where decisions must be made with incomplete information, changing conditions, and limited resources.
Traditional optimization approaches often assume stable models of the environment. In practice, however, industrial systems rarely behave in such a predictable way. Uncertainty, delayed effects of decisions, and partial observability are the rule rather than the exception.
These observations gradually led to the idea of building a research and engineering platform for studying adaptive decision-making systems.
This idea became the foundation of the StrataMar project.
What is StrataMar
StrataMar is a research initiative focused on the development of intelligent decision-support systems for complex environments.
The project explores how modern reinforcement learning methods can be combined with probabilistic reasoning, constrained optimization, and simulation-based experimentation in order to support decision-making in uncertain and dynamic systems.
Rather than focusing purely on prediction or purely on static optimization, the project investigates adaptive decision policies that evolve through interaction with simulated environments.
In practical terms, StrataMar aims to provide a framework where intelligent agents can learn how to operate in complex systems while respecting operational constraints such as safety, resource limitations, and economic costs.
Why Reinforcement Learning
Reinforcement learning provides a natural mathematical framework for modeling sequential decision processes.
In this framework an agent interacts with an environment over time and gradually improves its policy by observing the consequences of its actions.
This paradigm is particularly suitable for systems where:
- decisions are sequential
- system dynamics are uncertain
- the environment evolves over time
- actions have delayed consequences
Such problems naturally correspond to Markov Decision Processes and their extensions.
However, applying reinforcement learning in real operational environments raises additional challenges. Industrial systems often involve safety constraints, partial observability, and uncertain system dynamics.
Addressing these issues requires extending classical reinforcement learning approaches with ideas from decision theory and robust optimization.
Research Directions
The StrataMar project explores several interconnected research directions.
Decision-Making Under Uncertainty
Real systems rarely provide perfect information. Sensors can be noisy, system states may be partially observable, and unexpected events can occur.
For this reason the project investigates methods for representing and reasoning about uncertainty within reinforcement learning frameworks.
Hierarchical and Multi-Agent Systems
Large technical systems are rarely controlled by a single decision process. Instead they consist of multiple interacting subsystems operating at different temporal and functional scales.
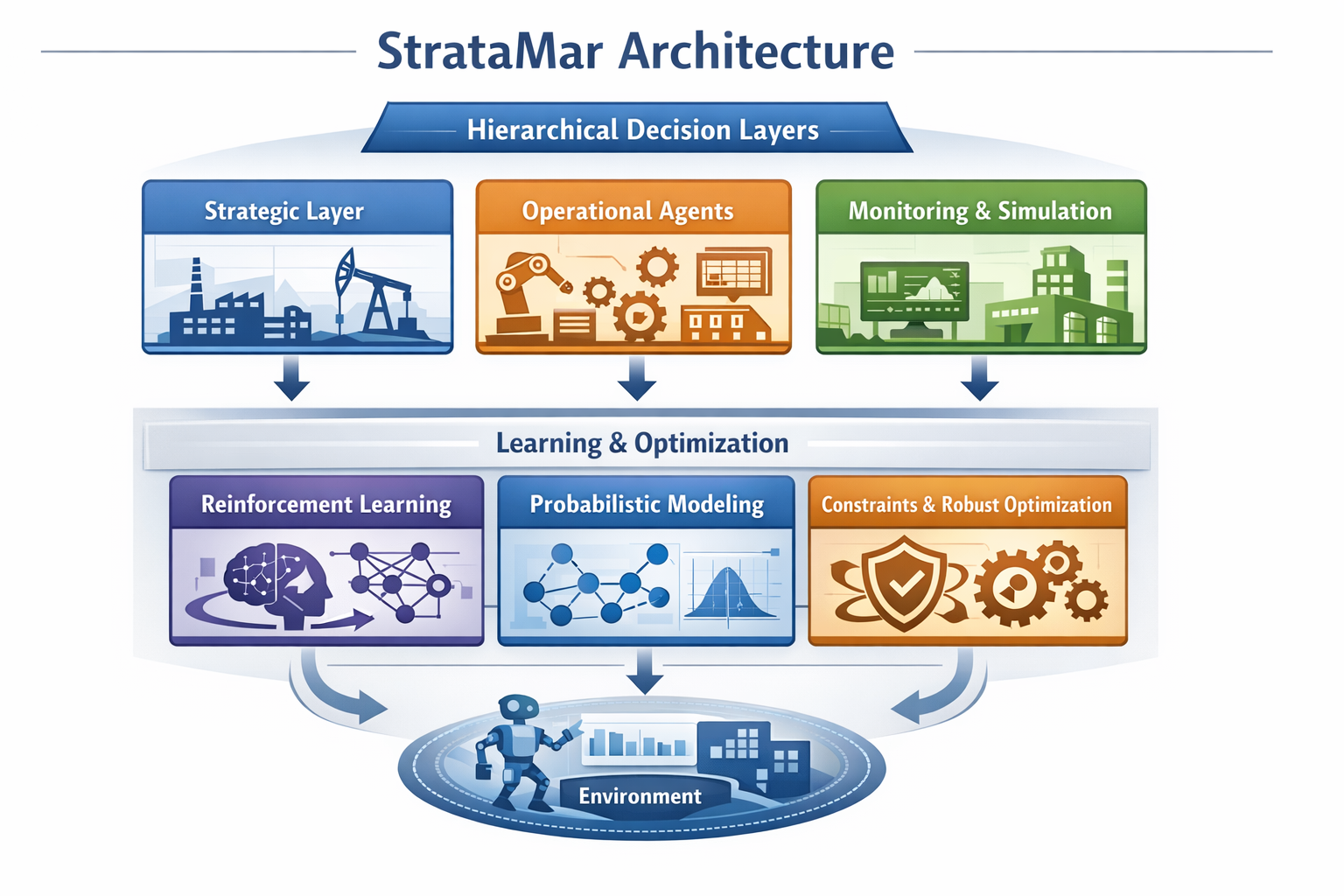
StrataMar explores hierarchical decision architectures where different layers are responsible for strategic planning, operational control, and local decision processes.
Constrained and Robust Reinforcement Learning
In industrial environments decisions must satisfy operational constraints such as safety requirements, resource availability, and economic limitations.
The project studies reinforcement learning methods that explicitly incorporate constraints and robustness considerations.
Simulation-Driven Experimentation
Before intelligent decision systems can be deployed in real-world environments they must be extensively tested.
A central component of the StrataMar initiative is therefore the development of simulation environments that allow experimentation with different decision policies and system configurations.
What Makes the Approach Different
Many existing industrial AI systems focus primarily on prediction. They estimate the probability of equipment failure, detect anomalies in sensor data, or forecast demand.
While prediction is useful, it does not directly answer the more important operational question:
What decision should be taken next?
Other systems rely on classical optimization techniques. These methods are effective when system models are well understood and relatively stable, but they often struggle in environments characterized by uncertainty and dynamic changes.
The StrataMar approach attempts to bridge this gap.
Instead of focusing only on prediction or only on optimization, the project investigates decision architectures that combine:
- sequential decision modeling
- reinforcement learning
- uncertainty-aware reasoning
- constrained optimization
- simulation-based validation
The goal is not simply to train agents that perform well in benchmark environments, but to explore the design of robust decision-support systems capable of operating in uncertain real-world conditions.
Architectural Perspective
A distinguishing feature of the StrataMar project is its architectural perspective.
Rather than designing a single intelligent agent, the system is conceptualized as a hierarchical decision architecture.
Different layers of the system operate at different time scales and levels of abstraction:
- strategic planning layers
- operational decision agents
- monitoring and simulation layers
This structure reflects the way complex technical systems are typically managed and enables coordination between multiple decision processes.
Relation to Ongoing Research
The StrataMar initiative is closely connected to my ongoing research on reinforcement learning and decision-making under uncertainty.
The broader objective of this work is to explore how ideas from reinforcement learning, probabilistic reasoning, and decision theory can be transformed into practical engineering tools.
In this sense StrataMar serves both as:
- a research platform for experimentation
- a prototype architecture for future decision-support systems
Looking Ahead
The project is currently in its early stages.
The immediate focus is on the development of the simulation environment and the core architecture of the platform.
Future work will include:
- experimental studies of reinforcement learning algorithms
- investigation of uncertainty modeling techniques
- development of hierarchical and multi-agent decision architectures
- exploration of real-world application scenarios
The long-term objective is to better understand how adaptive decision systems can operate in complex environments characterized by uncertainty, constraints, and evolving system dynamics.
This article marks the beginning of the StrataMar research initiative.
Project Links
Website: https://stratamar.net
Research Blog: https://logmaks.github.io